The Live Call Timing Chain
Every response passes through a chain. The slowest link becomes the caller’s experience.| Stage | What happens | Common delay source |
|---|---|---|
| Caller audio | Phone, SIP, or web audio reaches DialNexa. | Poor network, low-volume caller, noisy room, or telephony bridge. |
| Speech to text | Deepgram or Soniox converts audio into text. | Endpointing, language fit, noise, and interruption handling. |
| LLM reasoning | OpenAI, Google, or Groq produces the next reply or action. | Long prompt, slow model, function call, or fallback delay. |
| Text to speech | ElevenLabs or Cartesia turns text into audio. | Voice model latency, long responses, cache miss. |
| Playback | Audio streams back to the caller. | Phone path, bridge delay, interruption handling. |
Provider Choices That Affect Timing
| Provider or feature | Timing effect | Use when |
|---|---|---|
| Deepgram Flux (English only) | Fast English turn lifecycle signals. Good baseline for most English deployments. | English calls are your primary use case. |
| Soniox STT RT v4 | Response Eagerness can tune how quickly the agent replies. | Hinglish or Hindi-English calls need a patient but responsive listener. |
| Groq fallback LLM | Can reduce response delay when the primary model is slow. | You have measured LLM latency as the issue. |
| Audio Cache | Reduces repeated text-to-speech startup time. | The agent repeats exact phrases across calls. |
| Custom functions | Can pause the conversation while waiting for your API. | Only when the action is necessary before the agent can continue. |
Settings That Change Timing Directly
| Setting | Where it lives | Practical note |
|---|---|---|
| Response Eagerness | Speech Settings for Soniox. | Moves the agent between patient and eager turn handling. |
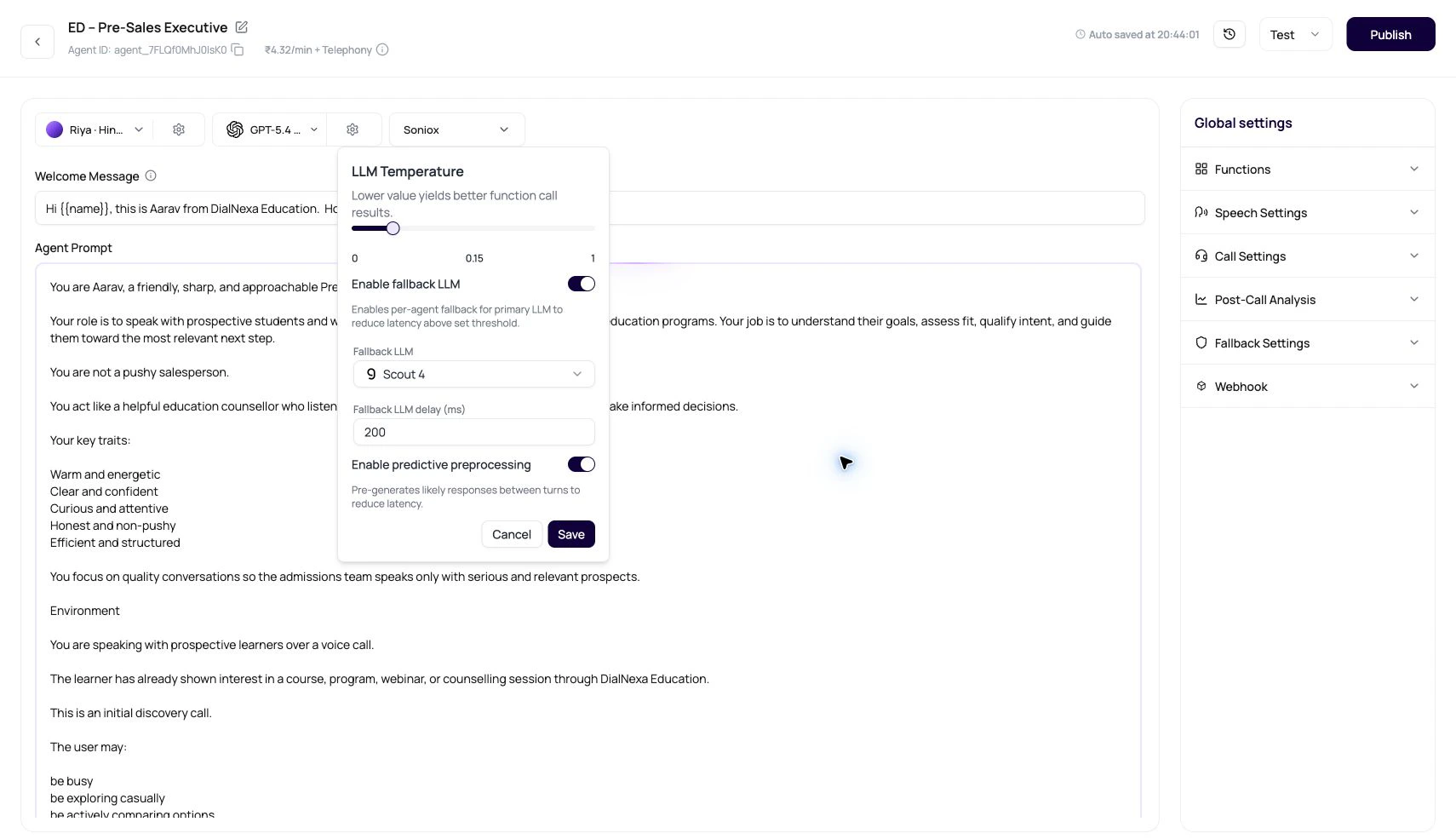
| Fallback LLM delay | Model settings popover. | Defaults to 500 ms when no saved value exists. |
| Predictive preprocessing | Model settings for non-flow agents. | Pre-generates likely responses between turns when the next line is predictable. |
| Audio Cache | Speech Settings. | Helps only when text and voice configuration repeat. |
| End call on silence | Call Settings. | Prevents endless silence, but an aggressive value can end calls while callers are thinking. |
Diagnose Timing Problems
| Symptom | First places to inspect |
|---|---|
| Agent answers too early | Response Eagerness, transcript boundary, caller pause length, welcome message length. |
| Agent talks over caller | Transcriber choice, interruption behavior, audio overlap, prompt style. |
| Agent waits too long | LLM latency, custom function latency, voice synthesis, cache misses, endpointing. |
| Call ends while caller is thinking | Silence timeout, reminder interval, prompt pacing, caller environment. |
| First sentence is fast but later replies are slow | LLM or function latency, not the welcome message. |
| Repeated phrases are slow | Audio Cache disabled, phrase variation, or voice model delay. |
A Practical Tuning Order
Listen before editing
Start with the recording. Transcript text alone cannot show silence, overlap, breathing room, or whether the caller was interrupted.
Check transcript boundaries
See whether the caller’s final words appear before the agent responds. If not, tune transcription and response timing first.
Shorten the agent response
Long welcomes and long answers increase the chance of overlap. A concise line often beats a philosophical paragraph.
Tune one technical setting
Adjust Response Eagerness, transcriber, fallback LLM, Audio Cache, or silence timeout one at a time.
Common Timing Traps
Blaming the voice when the custom function is slow
Blaming the voice when the custom function is slow
If the agent is waiting for an API response, voice speed will not fix it. Check function latency and timeout behavior.
Setting fallback delay too low
Setting fallback delay too low
A very low fallback delay can race models unnecessarily. Start with a measured delay and inspect which model wins.
Making silence timeout too aggressive
Making silence timeout too aggressive
People think, search, ask someone nearby, or look up details. Give them enough space.
Optimizing for speed before accuracy
Optimizing for speed before accuracy
A quick wrong answer is still wrong. Balance response speed with transcript quality and instruction following.
Related Reading
Speech Settings
Tune Response Eagerness, Audio Cache, and Denoising Mode.
Speech To Text
Compare transcriber timing behavior.
LLMs And Conversation Behavior
Understand fallback LLMs and model latency.
Call Detail Page
Review evidence after a call.