Start With The Call, Not The Provider
| Caller reality | Start with this stack | Why | Useful integration path |
|---|---|---|---|
| Mostly English support or sales calls. | Deepgram Flux, OpenAI, ElevenLabs or Cartesia after voice tests. | Balanced recognition, reasoning, and speech quality for first production tests. | HubSpot, Salesforce, Zendesk. |
| English calls where interruptions matter. | Deepgram Flux (English only), short prompt, low temperature, optional Groq fallback. | Flux is useful for sharper English turn boundaries. Short prompts reduce waiting. | Slack for urgent owner alerts. |
| Hindi-English or Hinglish callers. | Soniox, Hindi-English language, Hinglish Map, tested SmallestAI or ElevenLabs voice. | Soniox receives Hindi and English hints, and Hinglish Map helps the agent avoid stiff wording. SmallestAI has native Indian voice personas. | Google Sheets for review queues before scaling. |
| Indian English callers. | Soniox or Deepgram Flux, OpenAI, Sarvam AI (en-IN). | Sarvam AI provides natural Indian English voice output; Soniox handles Indian-accented speech well. | HubSpot, Salesforce. |
| Strict booking or payment flow. | Deepgram Flux (English) or Soniox based on language, OpenAI, low temperature, clear functions. | Structured work needs stable function calls and predictable extraction. | Google Calendar, Stripe. |
| Repeated outbound campaign script. | Stable transcriber, low-temperature model, Audio Cache on, short repeated lines. | Repeated phrases are cache-friendly, and short lines reduce speech delay. | Wati, Resend. |
| Ecommerce order calls. | Language-matched transcriber, clear voice for numbers, low-temperature model, order lookup function. | Order IDs, addresses, and amounts punish vague speech and vague prompts. | Shopify, Gmail. |
Compare Providers By Layer
Do not compare all providers in one pile. Each provider owns a different failure mode.| Layer | Public choices to compare | Good evidence | Bad comparison method |
|---|---|---|---|
| Speech to text | Deepgram Flux (English only) and Soniox in the current dashboard selector. | Recording plus live transcript plus accurate transcript. | Reading only the summary and blaming the model. |
| LLM | OpenAI, Google, Groq. | Function arguments, first token delay, response correctness, post-call fields. | Testing with different prompts for each model. |
| Text to speech | ElevenLabs, Cartesia, SmallestAI, Sarvam AI. | Recording, first audio delay, pronunciation, volume, caller comfort. | Choosing only from sample audio in the modal. |
| Telephony | Plivo number, SIP trunk, web call. | Same agent tested through each path. | Comparing a clean browser mic against a noisy mobile call. |
Provider Pages And Integration Pages
Some provider pages in the integration catalog are useful background reading. Use them as supporting context, not as a replacement for testing the provider inside a real DialNexa call.Deepgram
Useful when you are evaluating speech recognition tradeoffs.
ElevenLabs
Useful when voice identity and voice model choice matter.
OpenAI
Useful when comparing model behavior, function calling, and extraction.
Dashboard Integrations
Use this for Wati, Resend, and dashboard-managed action setup.
Workflow Integrations
Use this when the call result should trigger a workflow action.
Agent Integrations
Use this when the agent should act during the live call.
Provider Recipes You Can Start With
English default stack
English default stack
Use Deepgram Flux for English transcription, OpenAI for primary reasoning, and either ElevenLabs or Cartesia after listening tests. Keep temperature low when the agent calls functions or extracts structured results. This is a plain starting point, which is a compliment in production.
English interruption-heavy stack
English interruption-heavy stack
Use Deepgram Flux for English when callers interrupt often or answer in short bursts. Keep the welcome message short. Avoid long model replies. Test with callers who interrupt during the greeting, because they will.
Hindi-English stack
Hindi-English stack
Use Soniox with the Hindi-English language option. Turn on Hinglish Map when the agent sounds too formal. Test names, locality names, numbers, and casual mixed-language replies before publishing.
Fast fallback stack
Fast fallback stack
Choose a strong primary model first, then enable fallback LLM with a delay such as 500 ms as a starting point. Use Call History to confirm which model won the race and whether the winning response was still correct.
Repeated campaign stack
Repeated campaign stack
Keep greetings, disclosures, confirmations, and closing lines short and consistent. Audio Cache works best when the generated text and voice configuration repeat. Variables are useful, but they also make cache hits less likely.
Pricing Signals In The Builder
The dashboard shows rate previews so provider choice is not guesswork.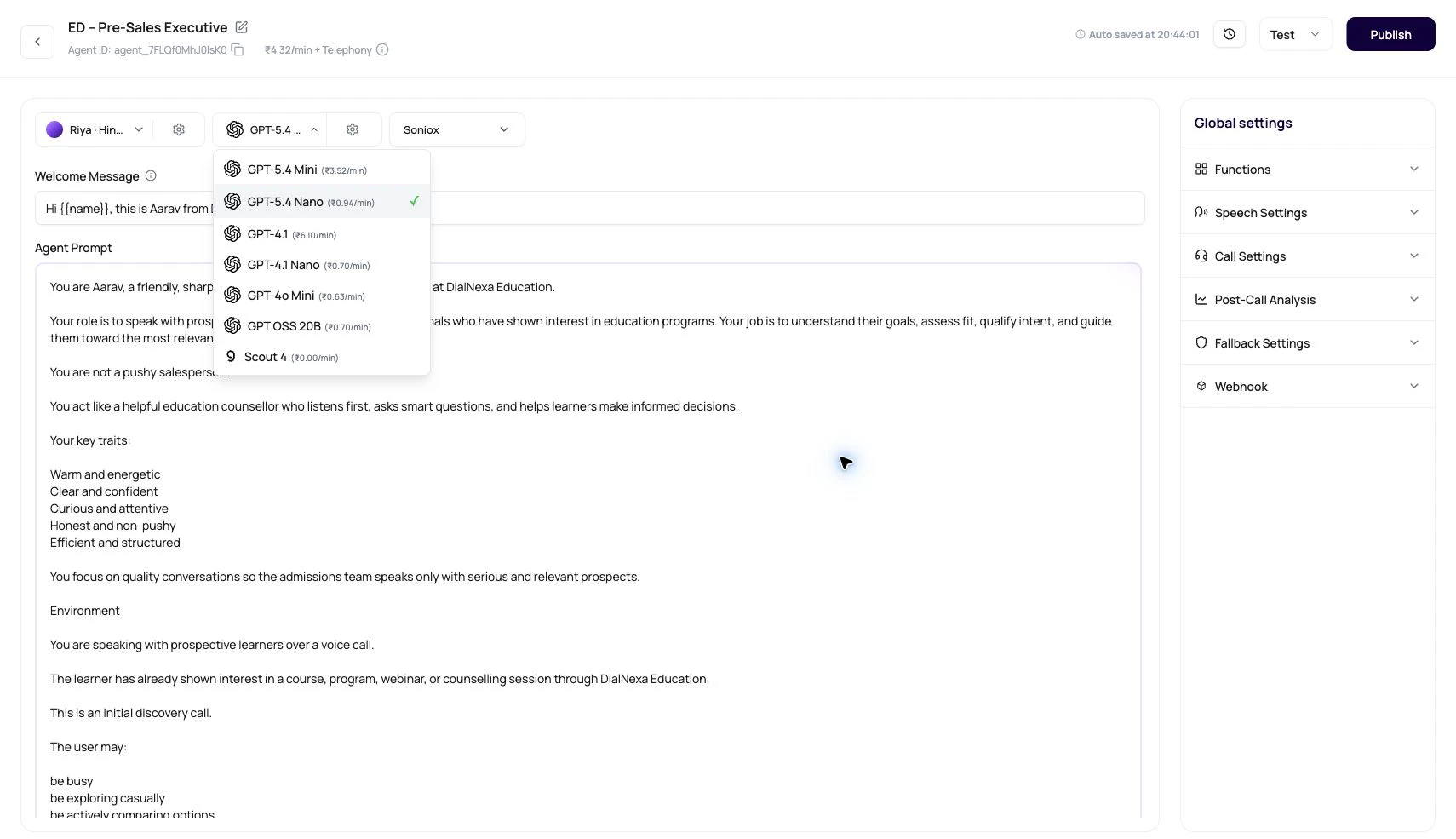
| UI area | What users can see |
|---|---|
| Model selector | INR per minute for available LLM models when the workspace uses the current billing preview path. |
| Transcriber selector | INR per minute beside transcriber options when pricing is available. |
| Pricing tooltip | Voice engine, LLM, transcriber, and telephony note in the agent builder. |
| SIP trunk modal | SIP trunking per-minute rate before saving a linked number. |
| Voice model data | Voice models can include per-minute pricing metadata when available. |
Telephony cost is separate from the voice, LLM, and transcriber stack. For Plivo-style routing, destination matching is based on the called number. For SIP trunking, DialNexa displays a flat SIP rate when it is configured.
Run A Fair Provider Test
Freeze the script
Use the same greeting, caller name, number, objection, pause, and final outcome for every test.
Freeze the route
Compare providers through the same phone path. Do not compare one provider on web call and another on a mobile network call.
Score the call detail
Review recording, live transcript, accurate transcript, summary, post-call fields, transfer data, Audio Cache, and cost.
Decision Shortcuts
| If the problem is | First place to look | Likely setting |
|---|---|---|
| Caller words are wrong in transcript. | Speech to text page and call recording. | Transcriber, language, noise, phone path. |
| Transcript is right but answer is wrong. | LLM page, prompt, functions, variables. | Model, temperature, prompt, function schema. |
| Agent takes too long to answer. | Latency page and model settings. | Endpointing, fallback LLM delay, function time, Audio Cache. |
| Agent sounds unnatural. | Text to speech page and recording. | Voice, voice model, speed, stability, volume, language. |
| Extracted fields are wrong. | Call detail and post-call analysis. | Transcript quality, field definitions, model behavior. |
Related Reading
Speech To Text
Compare Deepgram and Soniox behavior.
LLMs And Conversation Behavior
Tune model choice, temperature, fallback, and preprocessing.
Text To Speech And Voices
Compare ElevenLabs and Cartesia.
Languages Voices Models And Transcribers
Choose the complete agent stack.
Dashboard Integrations
Connect call outcomes to WhatsApp, email, workflows, and external systems.
Integration Catalog
Browse provider and business-system pages for connected workflows.