Model Families In DialNexa
Your workspace may show a subset of model families depending on what is enabled.| Model family | Use it when | Validate before production |
|---|---|---|
| OpenAI | You want the safest general-purpose default for prompts, functions, structured outputs, summaries, and post-call extraction. | Function arguments, response format, refusal wording, and behavior on long conversation history. |
| You want to compare reasoning, long-context behavior, or performance on your specific knowledge content. | Tool calling, summary consistency, and strict instruction following. | |
| Groq | You need fast model responses or a low-latency fallback where enabled. | Response length, function behavior, and whether speed still leaves enough reasoning quality. |
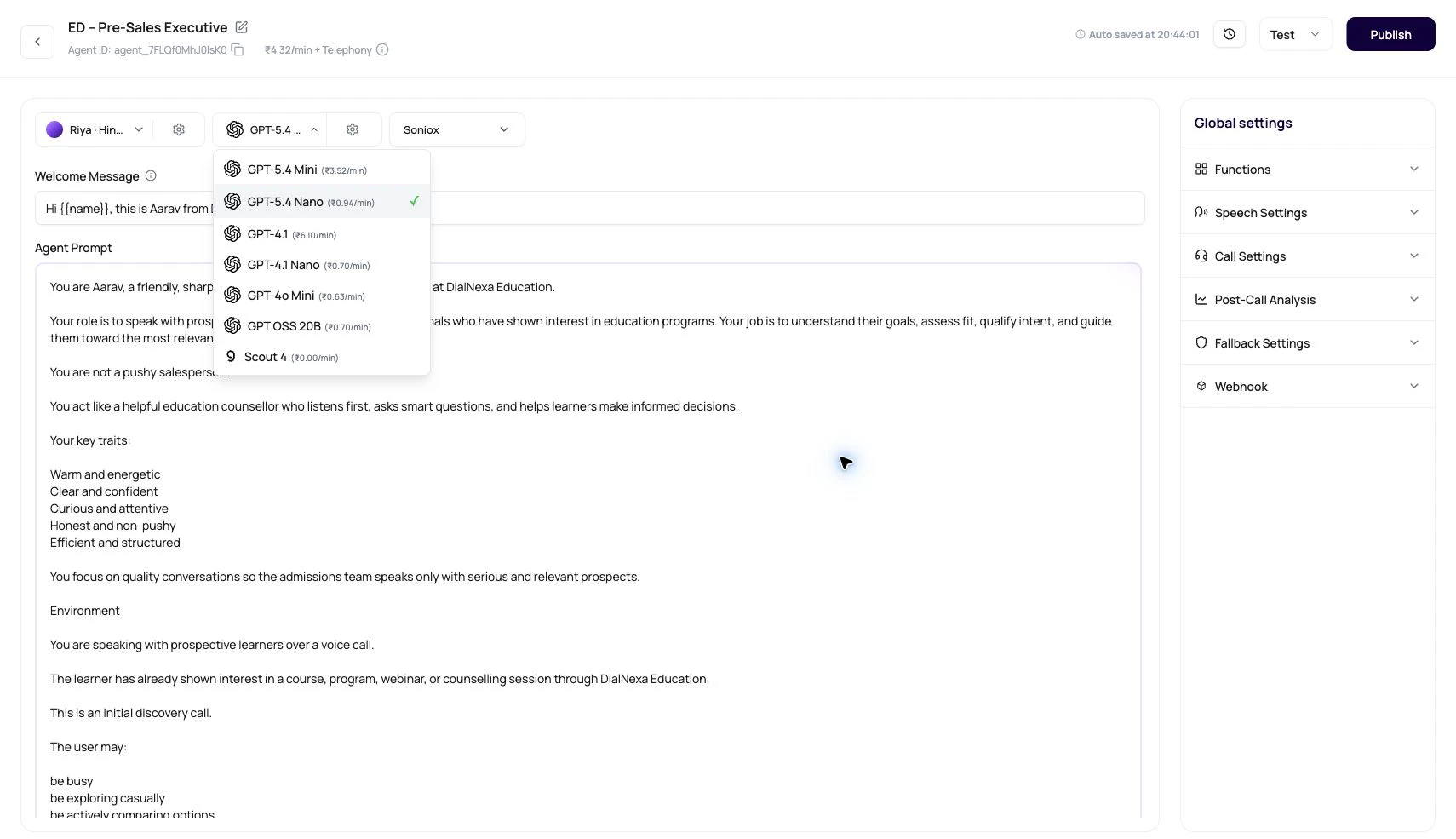
What The Model Selector Does
| Behavior | What users should know |
|---|---|
| Default model | New agents try to select GPT-4o Mini when it is available, otherwise the first available non-deleted model. |
| Pricing preview | The model selector can show ₹x.xx/min beside each model. |
| Published state | Published versions can disable model changes. Edit a draft when comparing models. |
| Provider logos | The selector visually distinguishes OpenAI, Google, and Groq model families. |
| Settings button | The settings popover controls temperature, fallback LLM, fallback delay, and predictive preprocessing. |
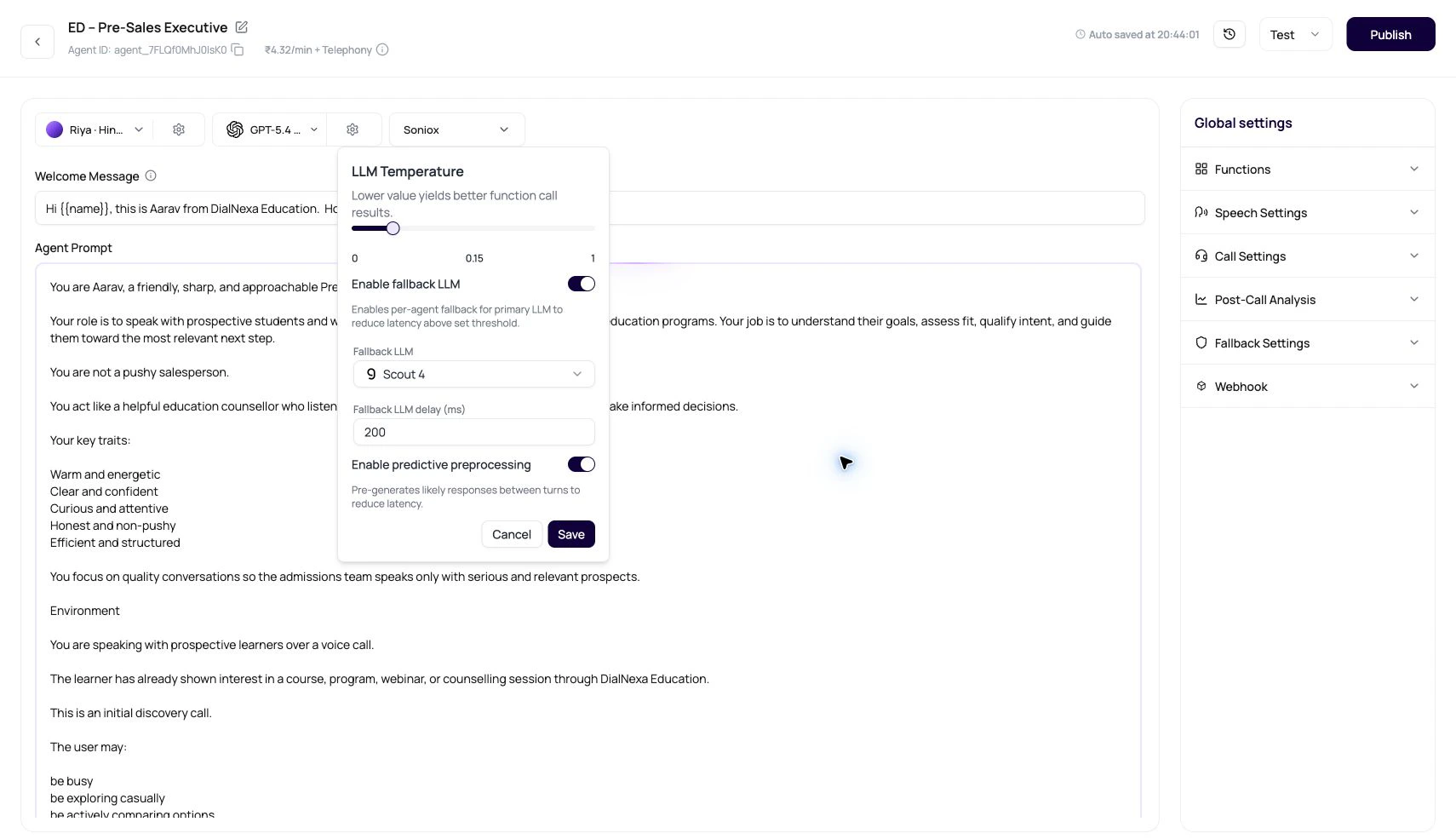
Temperature
The LLM Temperature slider runs from 0 to 1 in the dashboard. Lower values are better for function calls and structured results.| Call type | Suggested direction |
|---|---|
| Booking, payments, eligibility, compliance, or structured extraction. | Keep temperature low. Stable arguments matter more than colorful phrasing. |
| Support intake or objection handling. | Start low, then test a moderate value only if responses are too stiff. |
| Knowledge-heavy calls. | Keep temperature low until retrieval and answer quality are proven. |
| Regulated scripts. | Keep temperature low and write explicit allowed and disallowed behavior. |
Fallback LLM
Fallback LLM is a per-agent setting that can start a backup model after a configured delay. The default delay value in the dashboard is 500 ms when no saved value exists.Pick a strong primary model
Fallback is not a license to choose a weak primary. Start with the model that best follows your instructions.
Enable fallback for latency, not decoration
Use fallback when model response delay is a real caller problem.
Set the delay
A short value such as 500 ms is a practical starting point. Lower values can race too often. Higher values may be too late to help.
Choose the fallback model
When fallback is enabled and nothing is selected, the dashboard tries to pick an available fast fallback option where possible.
Predictive Preprocessing
Predictive preprocessing can pre-generate likely replies between turns for non-flow agents. The toggle is not shown for Conversational Flow Agents because flow behavior is explicit node logic.| Good fit | Poor fit |
|---|---|
| Repeated scripts, reminders, confirmations, and predictable objection paths. | Calls where the next line depends on a custom function result. |
| Agents with stable prompts and low variation between calls. | Agents with many dynamic variables in almost every sentence. |
| Short replies that commonly repeat. | Long exploratory conversations. |
Model Problems And First Fixes
The agent does not call functions correctly
The agent does not call functions correctly
Lower temperature, then improve function descriptions, required fields, examples, and error handling. Change model only after the function schema is clear.
The agent gives shallow answers
The agent gives shallow answers
Check whether knowledge content was retrieved and whether the prompt asks for the right depth. Then compare OpenAI and Google on the same call script.
The agent is slow
The agent is slow
Confirm whether delay comes from transcription, model generation, custom functions, text to speech, or telephony. Use fallback LLM only when the model is actually the slow part.
The agent changes behavior between calls
The agent changes behavior between calls
Reduce temperature, tighten instructions, and remove conflicting prompt sections. Then compare models with the same test script.
How Model Behavior Affects Integrations
When an agent calls a function or prepares data for a workflow, the model is responsible for deciding when the action is appropriate and which values are safe to pass.| User goal | Model responsibility | Read next |
|---|---|---|
| Book or reschedule something. | Ask for missing fields before calling the booking action. | Functions, Google Calendar. |
| Update a CRM. | Separate confirmed caller facts from guesses. | HubSpot, Salesforce. |
| Send an email or WhatsApp message. | Avoid promising a message before the required recipient and content are known. | Email with Resend, WhatsApp with Wati. |
| Escalate a support case. | Summarize the issue, priority, and promised next step without inventing details. | Zendesk, Intercom, Slack. |
Related Reading
Prompts And Welcome Messages
Write the instructions the model follows.
Functions
Give the model safe actions.
Custom Functions
Connect actions to your APIs.
Provider Selection Guide
Choose model, voice, and transcriber together.