The caller does not hear your provider architecture. They hear a voice saying their name, amount, date, and next step. Test those words.
Choosing A Provider
| Provider | Use it when | Test before publishing |
|---|---|---|
| ElevenLabs | You want broad voice auditioning, strong speaker personality, and a familiar provider for brand voice work. | Flash v2.5 behavior, names, numbers, speed, stability, and long compliance lines. |
| Cartesia | You want fast streamed speech, clean call audio, and language-aware voice output. | Language fit, volume, speed, and repeated short phrases. |
| SmallestAI | Your agent targets Indian callers and you need a natural Indian-accented voice (Hindi, Hinglish, Indian English). | Indian names, locality names, and mixed-language phrases. |
| Sarvam AI | Your agent addresses Indian English (en-IN) callers and you want a locally natural voice experience. | Indian English pronunciation, numbers, and dates in Indian format. |
- Choose ElevenLabs
- Choose Cartesia
- Choose SmallestAI
- Choose Sarvam AI
- Compare providers
Choose ElevenLabs when the voice personality matters and you want to audition a wider library. In the current dashboard path, ElevenLabs agent versions are standardized on Flash v2.5 (
eleven_flash_v2_5) where supported, so treat that as the main model to test.How The Voice Selector Works
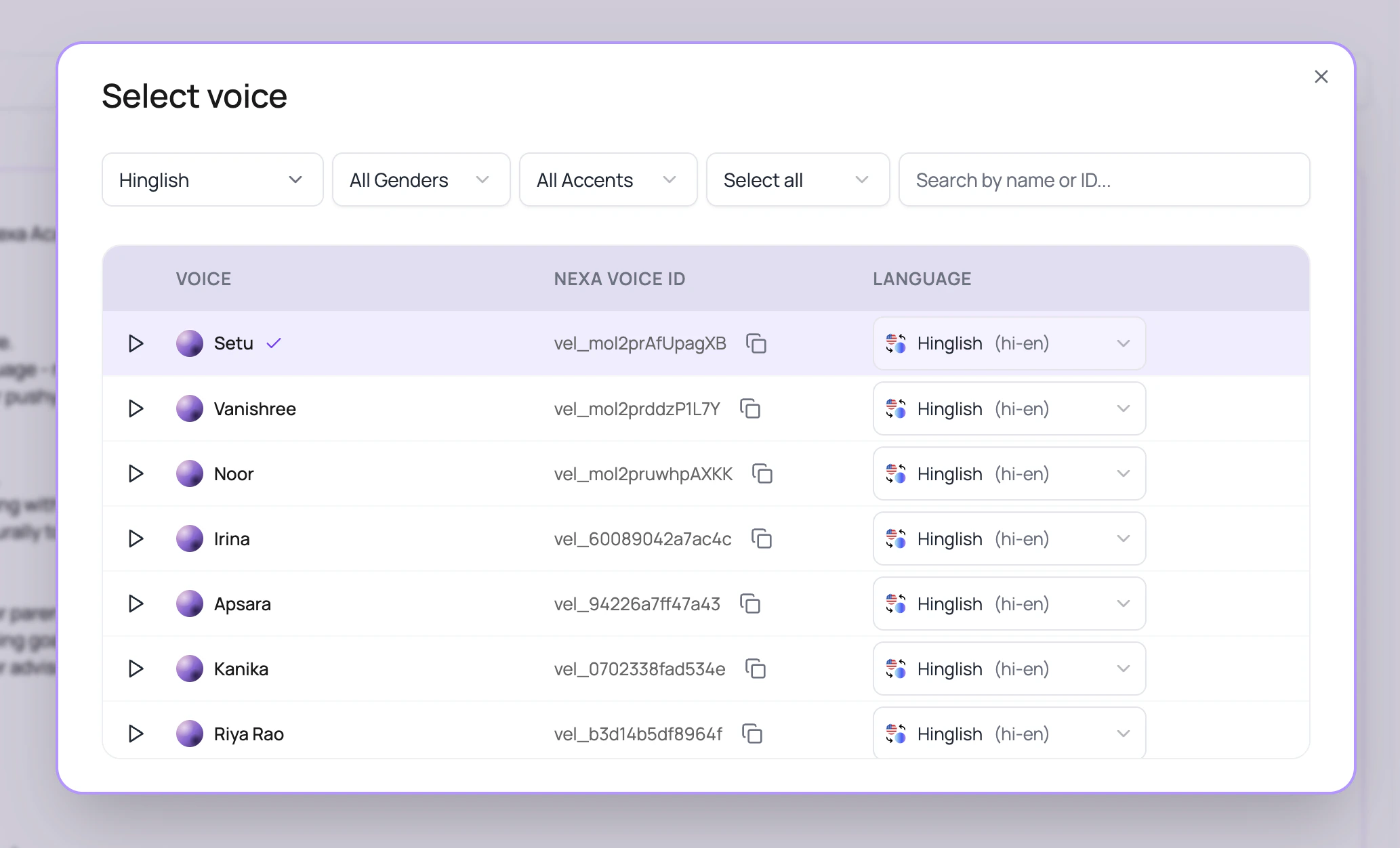
The selector is designed for large voice libraries.| UI control | What it does |
|---|---|
| Provider filter | Shows all public voices, only ElevenLabs voices, or only Cartesia voices. |
| Language filter | Filters by languages supported by available voices. English is the starting filter in the current modal. |
| Gender filter | Narrows visible rows to male or female where the voice record includes that label. |
| Accent filter | Uses provider-specific accent metadata exposed by the voice records. |
| Search | Matches voice name, provider voice id, internal voice id, voice_ id, and vel_ Nexa voice id. |
| Sample playback | Plays the sample recording for quick auditioning. |
| Nexa voice ID | Lets users copy the vel_ voice id for notes or API-adjacent setup. |
| Row language selector | Picks the exact language for that voice before applying it to the agent. |
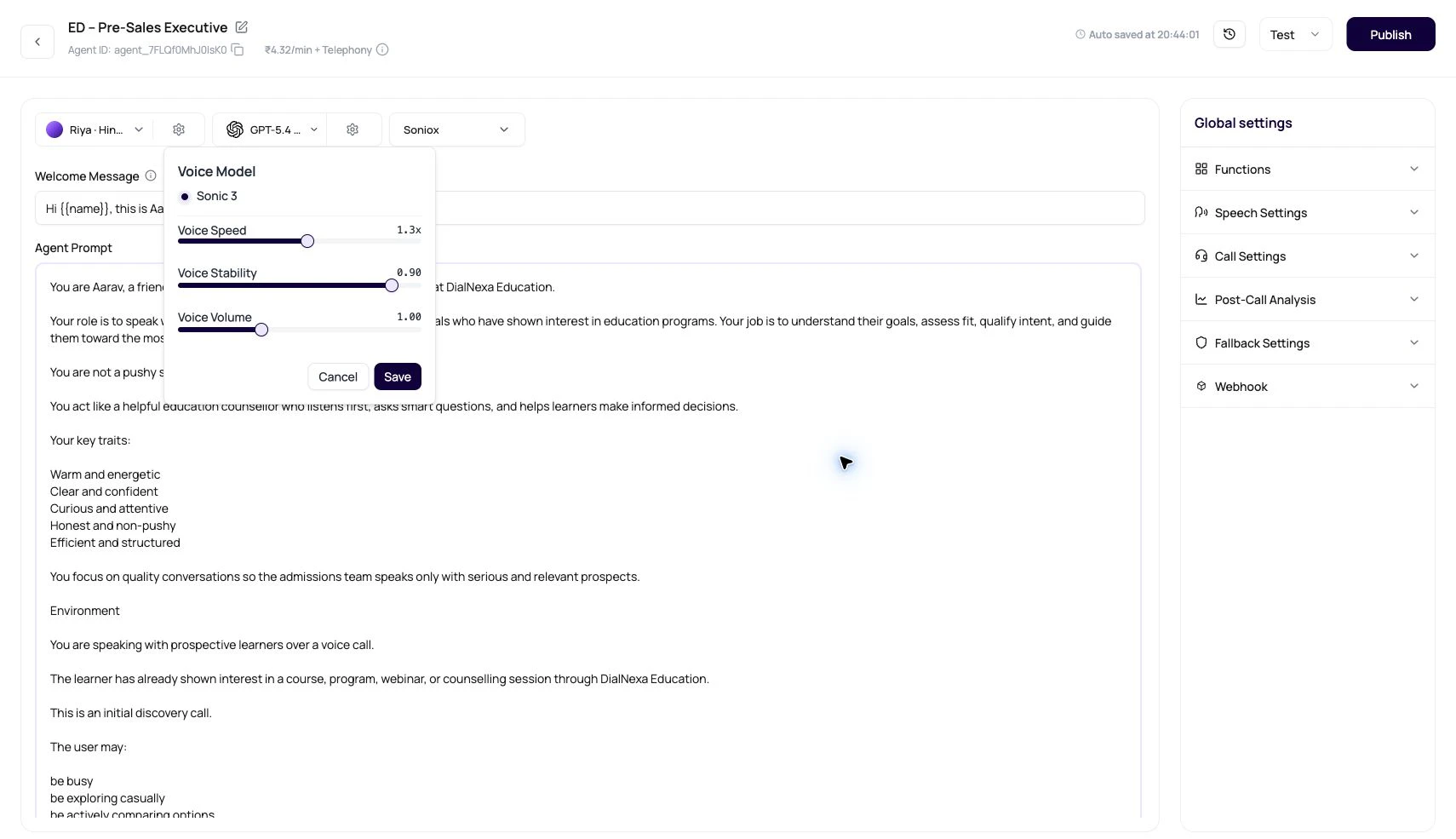
Voice Settings In The Popover
| Setting | What users change | Practical test |
|---|---|---|
| Voice Model | The synthesis model available for the current voice. | Start with the visible model choice for the selected voice. For ElevenLabs, test Flash v2.5 where shown. |
| Voice Speed | How quickly the agent speaks. | Read dates, amounts, phone numbers, and local names. Faster speech usually fails there first. |
| Voice Stability | How much variation the voice has. Lower values can sound more emotional; higher values can sound calmer. | Repeat the same line three times and check consistency. |
| Voice Volume | Output loudness in the call path. | Listen through speaker mode, headphones, and the actual telephony route. |
Audio Cache And Repeated Speech
Audio Cache stores synthesized audio for repeated phrases. It works best when the generated text, voice provider, voice id, voice settings, and output format repeat.| Cache-friendly phrase | Why it works |
|---|---|
| A fixed welcome line. | Same text and same voice configuration repeat across calls. |
| A compliance disclosure. | Usually identical and latency-sensitive. |
| A short confirmation. | Repeats often and starts quickly when cached. |
| Cache-unfriendly phrase | Why it misses |
|---|---|
| A line with caller name, amount, or time. | Variables change the text. |
| A long model-generated explanation. | The model may phrase it differently each turn. |
| A reply based on fresh API data. | External data changes the output. |
Where Voice Quality Shows Up Outside The Call
Voice quality is not only a caller comfort issue. It changes whether downstream work is trusted.| Downstream work | Why voice quality matters | Helpful links |
|---|---|---|
| Written confirmations. | If the caller misheard a date or amount, the follow-up message may look surprising or wrong. | Email with Resend, Gmail. |
| Sales handoff. | A confident summary is less useful if the caller struggled to understand the agent. | HubSpot, Salesforce. |
| Support escalation. | The recording helps the support owner judge tone, not only the transcript text. | Zendesk, Intercom. |
| Repeated campaigns. | Cache-friendly fixed lines can reduce perceived delay on common phrases. | Audio Cache monitoring. |
Voice Review Checklist
Test the first sentence
The welcome line sets trust. Check pace, pronunciation, greeting tone, and whether the voice fits the use case.
Test difficult words
Include brand terms, product names, locality names, acronyms, medicine names, plan names, and agent names.
Test numbers and dates
Amounts, due dates, order IDs, phone numbers, and appointment slots reveal speech issues quickly.
Test interruption recovery
Interrupt the agent during the greeting and check how naturally it resumes.
Related Reading
Supported Voices And Models
Review voice fields and model fields.
Speech Settings
Enable Audio Cache and tune speech behavior.
Multilingual And Hinglish Calls
Match voice, language, and transcriber.
Audio Cache Monitoring
Read cache evidence on the call detail page.